La livraison logicielle moderne exige des pipelines automatisés et reproductibles qui détectent les bugs tôt, déploient en toute confiance et s'adaptent à la vélocité de l'équipe. Le choix de la plateforme CI/CD façonne l'ensemble de votre workflow DevOps—des commits locaux aux déploiements en production. Ce guide FlowZap présente des configurations de pipelines de production pour les 10 plateformes les plus adoptées en 2025, avec des diagrammes FlowZap visuels et des fichiers FlowZap Code, montrant l'exécution parallèle, les portes de sécurité et les patterns de promotion d'environnement utilisés par les équipes d'ingénierie qui livrent du code quotidiennement.
1. GitHub Actions : Workflows Cloud Événementiels
Contexte : GitHub Actions domine pour les équipes open-source et natives GitHub (62% d'utilisation sur projets personnels selon JetBrains 2025). Ses workflows basés sur YAML se déclenchent sur plus de 20 types d'événements (push, PR, schedule, workflow_dispatch), avec un marketplace de plus de 18 000 actions réutilisables. À utiliser quand votre code est sur GitHub et que vous avez besoin d'un CI sans configuration avec des tests matriciels sur plusieurs versions OS/langage.
Pourquoi les Développeurs le Choisissent : Intégration étroite avec les fonctionnalités GitHub (protection de branches, vérifications PR, Dependabot), offre gratuite généreuse (2 000 minutes/mois), et runners auto-hébergés pour les charges sensibles. Les builds matriciels testent sur Node 18/20/22 + Ubuntu/Windows simultanément.
Patterns de Production : Filtrage par chemin pour monorepos (paths: ['api/**']), actions composites pour configs DRY, OIDC pour auth AWS/Azure sans secrets, et règles de protection de déploiement nécessitant une approbation manuelle pour la prod.
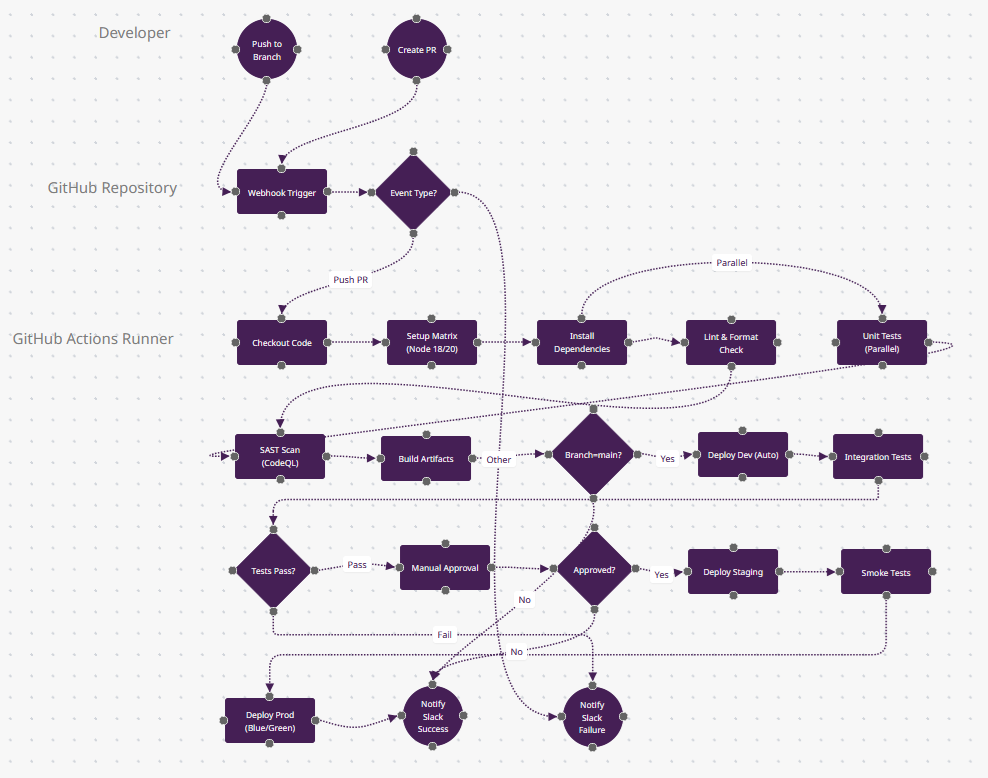
Ce qui Rend GitHub Actions Différent
- Builds Matriciels (n6) : Le nœud "Setup Matrix" représente la fonctionnalité phare de GitHub Actions—une seule config YAML génère des jobs parallèles sur Node 18/20/22 + Ubuntu/Windows/macOS simultanément. Cela signifie que n9 (Tests Unitaires) s'exécute en fait 6+ fois en parallèle. Aucune autre plateforme ne rend les tests multi-plateformes aussi simples.
- Flexibilité Événementielle (n4) : Le losange "Event Type?" gère plus de 20 types de déclencheurs (push, PR, schedule, workflow_dispatch, repository_dispatch). Vous pouvez déclencher des workflows depuis les commentaires GitHub Discussions ou même des webhooks externes—une flexibilité architecturale que Jenkins nécessite des plugins pour atteindre.
- Authentification OIDC (invisible entre n13→n18) : Les déploiements utilisent la fédération OpenID Connect—pas de clés secrètes AWS stockées dans GitHub Secrets. Votre workflow obtient des credentials temporaires directement depuis AWS STS. Seuls GitHub Actions et GitLab CI offrent cela nativement en 2025.
- Workflows Réutilisables (non montré) : En production, n10 (Scan SAST) appellerait un .github/workflows/security.yml centralisé depuis un autre repo—DRY sur plus de 100 projets. Ce modèle "workflow comme dépendance" est unique à GitHub.
- Quand Choisir : Votre code est sur GitHub, vous avez besoin d'un CI sans infrastructure, ou vous voulez 2 000 minutes gratuites/mois pour les repos publics. Dominant dans l'open-source (62% d'adoption selon JetBrains 2025).
2. GitLab CI/CD : DevSecOps Tout-en-Un
Contexte : GitLab CI/CD mène l'adoption entreprise (31,9% selon Developer Nation) grâce à son SCM+CI+CD+sécurité intégré en une seule plateforme. Les pipelines définis dans .gitlab-ci.yml utilisent des stages (build→test→deploy) avec support DAG pour les dépendances complexes. Idéal pour les équipes nécessitant la conformité (SOC2/HIPAA) avec scan de conteneurs intégré, SAST/DAST, et vérifications de licences.
Pourquoi les Développeurs le Choisissent : Templates Auto DevOps pour Kubernetes, review apps qui créent des environnements éphémères par MR, et passage d'artefacts entre jobs sans stockage externe. Les pipelines multi-projets déclenchent les repos en aval.
Patterns de Production : Pipelines enfants dynamiques pour monorepos, environnements protégés avec approbations de déploiement, GitLab Pages pour la documentation, et agent Kubernetes pour un accès sécurisé au cluster.
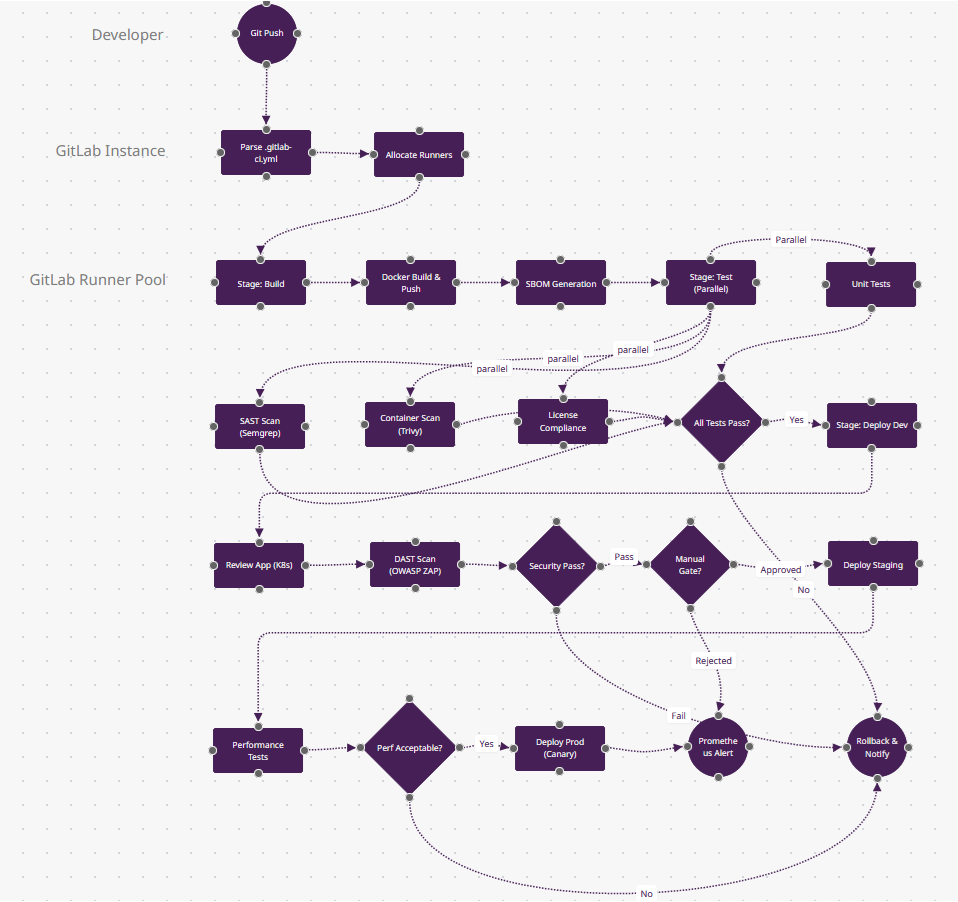
Ce qui Rend GitLab CI/CD Différent
- DevSecOps Tout-en-Un (stage parallèle n9-n11) : Quatre scans de sécurité (SAST, conteneur, DAST, conformité de licence) s'exécutent en un seul stage sans installation de plugin. GitLab inclut Semgrep, Trivy et OWASP ZAP prêts à l'emploi—Jenkins aurait besoin de 12 plugins pour une couverture équivalente.
- Review Apps (n14) : Ce n'est pas juste "déployer en dev"—GitLab crée des environnements Kubernetes éphémères par merge request avec des URLs uniques (feature-branch-abc.review.example.com). Automatiquement détruits à la fermeture de la MR. Des previews style Heroku pour n'importe quelle stack.
- Pipelines DAG (simplifié ici) : En production, n8-n11 pourraient avoir des dépendances complexes (
needs: [job-x, job-y]) au lieu de stages linéaires—exécuter les migrations de base de données en parallèle avec les builds frontend s'ils ne dépendent pas l'un de l'autre. Seuls GitLab + Tekton supportent une vraie exécution DAG. - Container Registry + Agent Kubernetes (n5→n14) : L'image Docker construite en n5 vit dans le registry intégré de GitLab (pas DockerHub), et n14 déploie via l'agent Kubernetes de GitLab—pull-based comme Argo CD, pas push-based comme la plupart des CI/CD. Cela élimine le stockage des credentials du cluster.
- Quand Choisir : Vous avez besoin de rapports de conformité (SOC2/HIPAA), voulez SCM+CI+CD+sécurité en une seule plateforme, ou gérez des monorepos multi-projets. Mène l'adoption entreprise (31,9% selon Developer Nation).
3. CircleCI : Pipelines Cloud Optimisés pour la Vitesse
Contexte : CircleCI optimise la vitesse de build via le caching intelligent, le parallélisme (répartir les tests sur 50 conteneurs), et les classes de ressources (scaling CPU/RAM). La config dans .circleci/config.yml utilise des Orbs—packages réutilisables pour AWS, Kubernetes, Slack—réduisant le boilerplate de 90%. Idéal pour les équipes priorisant des boucles de feedback sous 5 minutes sur des charges Docker/ARM.
Pourquoi les Développeurs le Choisissent : Débogage SSH dans les builds échoués, caching des couches Docker (rebuilds 10x plus rapides), répartition des tests par données de timing, et support de première classe pour les runners Apple Silicon (M1/M2).
Patterns de Production : Persistance du workspace pour les artefacts, workflows planifiés pour les scans de sécurité nocturnes, et jobs d'approbation pour les déploiements par étapes. Le dashboard Insights suit le MTTR et les tests instables.
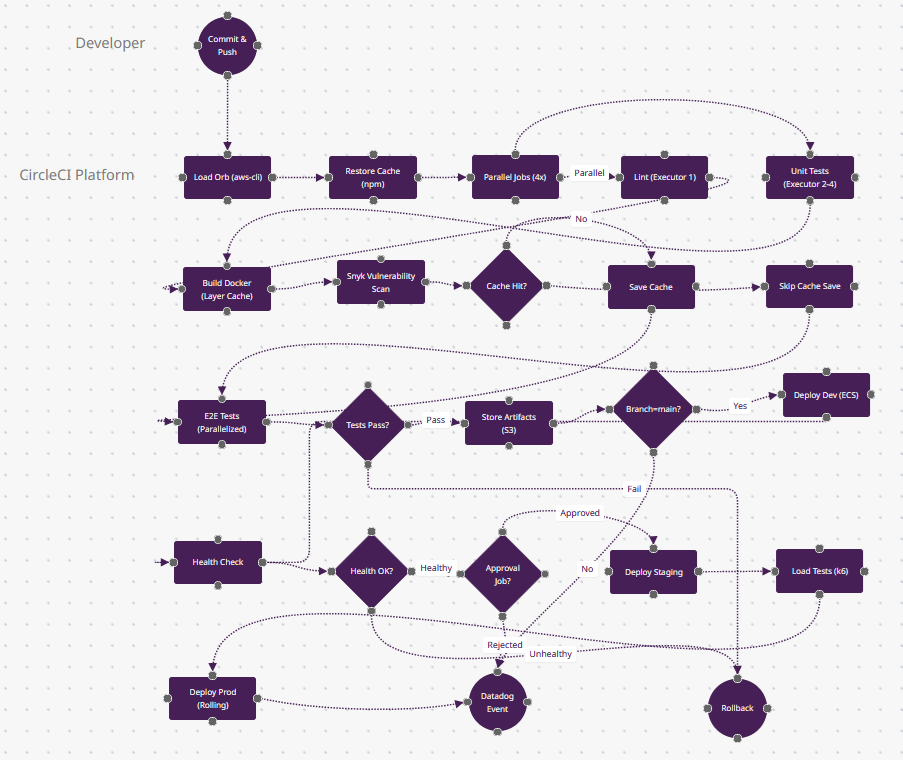
Ce qui Rend CircleCI Différent
- Caching Intelligent (n9-n11) : Le losange "Cache Hit?" utilise les données de timing des builds précédents—si package-lock.json n'a pas changé, n11 (Skip Cache Save) économise 2 minutes. Mais CircleCI cache aussi les couches Docker (n7)—reconstruire un Dockerfile avec des images de base inchangées prend des secondes, pas des minutes.
- Répartition des Tests par Timing (n12) : "E2E Tests (Parallelized)" répartit vos 500 tests Cypress sur 50 conteneurs basés sur les données de timing historiques—les tests lents obtiennent des conteneurs dédiés. Vous ne shardez pas manuellement ; l'API de CircleCI le fait. Cela fait finir n12 en 1/50ème du temps.
- Classes de Ressources (invisible) : Derrière les jobs parallèles n5-n6, vous choisissez CPU/RAM (small/medium/large/GPU). Exécutez le linting sur un petit exécuteur (0,0006$/min), les builds Docker sur xlarge (8 CPU, 16GB). Les autres outils vous donnent "un runner"—CircleCI vous permet d'optimiser le coût par job.
- Débogage SSH (non montré mais critique) : Quand n13 (Tests Pass?) échoue, vous pouvez SSH directement dans le conteneur échoué, lister le système de fichiers, et relancer les commandes. Jenkins nécessite VNC + plugins ; CircleCI le fait en un clic.
- Quand Choisir : La vitesse de build est critique (boucles de feedback sous 5 minutes), vous êtes orienté Docker, ou vous avez besoin de runners Apple Silicon (M1/M2) pour les builds iOS. Domine le CI d'apps mobiles (échelle Airbnb, Spotify).
4. Jenkins : Serveur d'Automatisation Riche en Plugins
Contexte : Jenkins détient 46% de parts de marché en entreprise grâce à plus de 1 800 plugins couvrant chaque outil (Jira, SonarQube, Kubernetes, Terraform). Les pipelines dans Jenkinsfile (DSL Groovy) offrent une syntaxe déclarative ou scriptée. Auto-hébergé on-prem ou cloud, c'est le choix pour les industries réglementées (finance/santé) nécessitant des builds isolés.
Pourquoi les Développeurs le Choisissent : Builds distribués sur des pools d'agents (Linux/Windows/macOS), UI Blue Ocean pour l'édition visuelle de pipelines, et post-actions scriptables (Slack en cas d'échec). Supporte tous les SCM (Git, SVN, Perforce).
Patterns de Production : Bibliothèques partagées pour fonctions Groovy réutilisables, Jenkins Configuration as Code (JCasC) pour la reproductibilité, et pipelines multibranches découvrant automatiquement les branches de fonctionnalités.
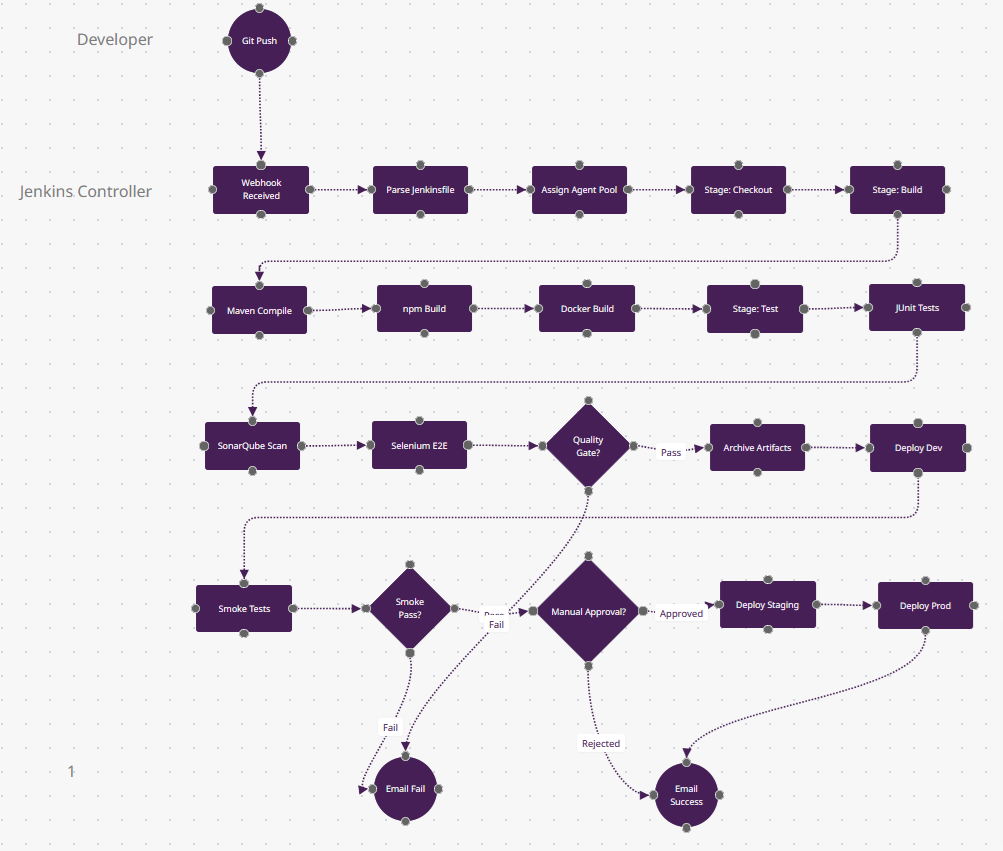
Ce qui Rend Jenkins Différent
- Écosystème de Plugins (tests parallèles n10-n12) : Ces trois nœuds de test pourraient intégrer SonarQube (qualité de code), Selenium Grid (multi-navigateurs), JUnit (Java), pytest (Python), et Jest (JS)—le tout via les 1 800+ plugins de Jenkins. Le losange n14 "Quality Gate?" peut appliquer des règles personnalisées de n'importe quel outil. Aucune autre plateforme n'a cette étendue de plugins.
- Builds Distribués (n3) : "Assign Agent Pool" route n6 (Maven) vers un agent Linux, n7 (npm) vers un agent Windows, et n8 (Docker) vers un agent GPU—tous dans différents data centers. L'architecture contrôleur-agent de Jenkins scale à plus de 1 000 agents. GitHub Actions facture à la minute ; Jenkins utilise votre matériel.
- Scripting Groovy (invisible) : Le Jenkinsfile est du code Turing-complet—n18 "Manual Approval?" pourrait interroger une base de données, appeler une API, ou parser des champs Jira avant de décider. CircleCI/GitLab utilisent du YAML déclaratif ; Jenkins est de la programmation impérative.
- Visualisation Blue Ocean (post-exécution) : Après la fin de ce pipeline, Blue Ocean rend un flowchart visuel du chemin d'exécution—quels jobs parallèles ont échoué, combien de temps chaque stage a pris. Le n23 "Email Failure" inclut un SVG du chemin échoué.
- Quand Choisir : Vous êtes dans une industrie réglementée (finance/santé) nécessitant des builds on-prem/isolés, vous avez des workflows multi-branches complexes, ou vous devez intégrer des outils legacy (SVN, Perforce). Détient 46% de parts de marché entreprise pour cette raison.
5. Azure DevOps : Intégration de l'Écosystème Microsoft
Contexte : Azure Pipelines domine les environnements Microsoft (32% d'utilisation) avec des workflows YAML ou designer classique. Les pipelines multi-stages gèrent CI+CD dans une seule config, avec des intégrations natives pour les services Azure (AKS, App Service, Key Vault). À utiliser pour les projets .NET/C# ou les équipes déjà sur Azure/Microsoft 365.
Pourquoi les Développeurs le Choisissent : Agents hébergés Microsoft (Windows/Linux/macOS), connexions de service pour AWS/GCP, analytics de tests via Azure Test Plans, et intégration Boards liant les commits aux work items.
Patterns de Production : Groupes de variables depuis Key Vault, portes de déploiement (interroger Azure Monitor avant la prod), feeds d'artefacts pour packages NuGet/npm, et templates YAML pour configs DRY.
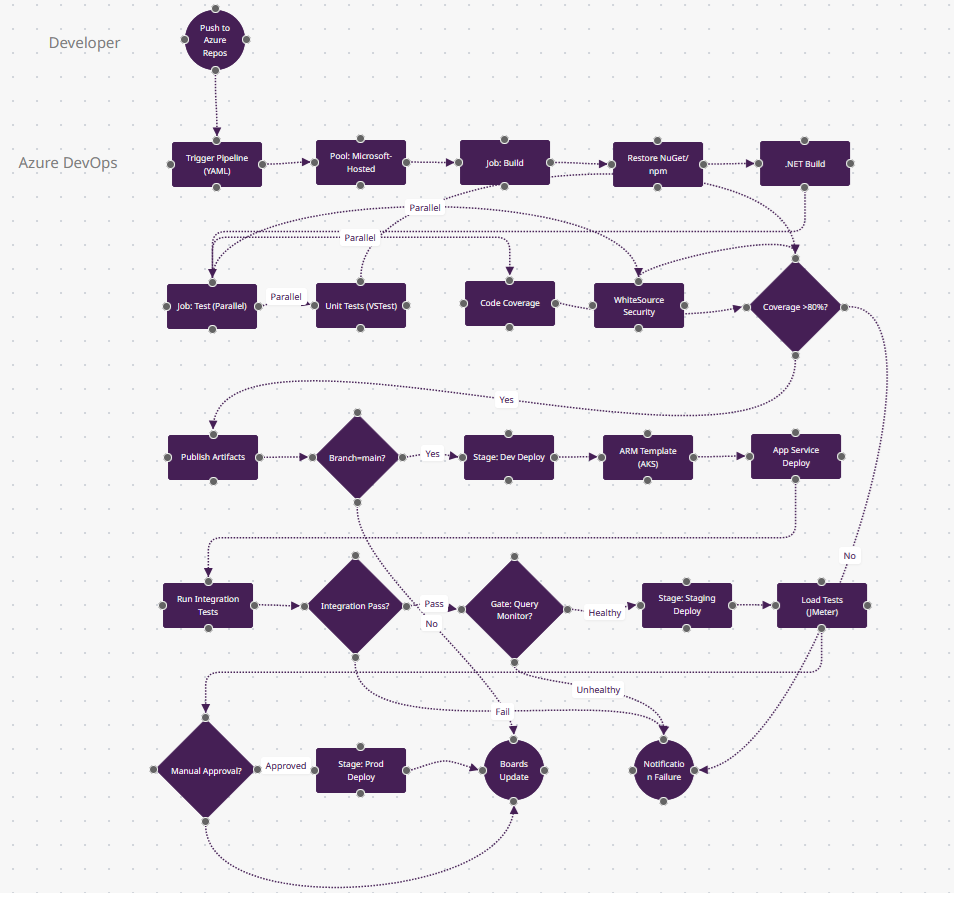
Ce qui Rend Azure DevOps Différent
- Groupes de Variables depuis Key Vault (n11-n12) : La porte "Coverage >80%?" utilise un seuil stocké dans Azure Key Vault—rotez la valeur sans éditer le YAML. Entre n14-n23, les chaînes de connexion et clés API sont tirées de Key Vault par environnement (dev/staging/prod). Rotation native des secrets que les autres outils nécessitent des plugins Vault pour obtenir.
- Portes de Déploiement (n19) : "Gate: Query Monitor?" met le pipeline en pause et interroge Azure Monitor pendant 15 minutes—si le taux d'erreur <1%, continuer ; sinon auto-abandon. Ce n'est pas une approbation manuelle ; c'est une vérification continue interrogeant les logs Kusto. Seuls Azure DevOps et Harness ont cela intégré.
- Intégration Boards (n24) : "Boards Update" est une action de première classe—ce déploiement déplace automatiquement le work item #4521 de "In Progress" à "Deployed to Prod" et le tague avec le numéro de build. GitHub Actions nécessite des webhooks ; Azure DevOps utilise une base de données partagée.
- YAML Multi-Stage (structure ici) : Un seul azure-pipelines.yml définit n4-n12 (CI), n13-n18 (deploy dev), n20-n21 (staging), n23 (prod)—avec dépendances de stages. Le CI/CD classique sépare build/release ; Azure les unifie avec des approbations de déploiement en YAML.
- Quand Choisir : Vous êtes un environnement Microsoft (.NET/C#/Azure), avez besoin de l'intégration Boards/Repos/Pipelines, ou voulez des agents hébergés Microsoft (Windows/Linux/macOS) sans gérer l'infrastructure. Domine l'écosystème .NET (32% d'utilisation).
6. Harness : Livraison Continue Propulsée par l'IA
Contexte : Harness apporte la vérification et le rollback pilotés par IA au CD, analysant les logs/métriques (Datadog, New Relic) pour auto-détecter les échecs de déploiement. Les pipelines YAML supportent les stratégies canary, blue-green et rolling avec optimisation des coûts (éteindre dev la nuit). Idéal pour les équipes SRE gérant plus de 100 microservices.
Pourquoi les Développeurs le Choisissent : Vérification Continue (l'IA compare les métriques), rollback automatisé sur détection d'anomalie, RBAC pour la conformité, et dashboards de coûts cloud. Le modèle basé sur les services abstrait la complexité Kubernetes.
Patterns de Production : Livraison progressive (canary 10%→50%→100%), politiques d'approbation (nécessite 2 SREs), provisionnement d'infrastructure via Terraform, et sync GitOps depuis les repos de config.
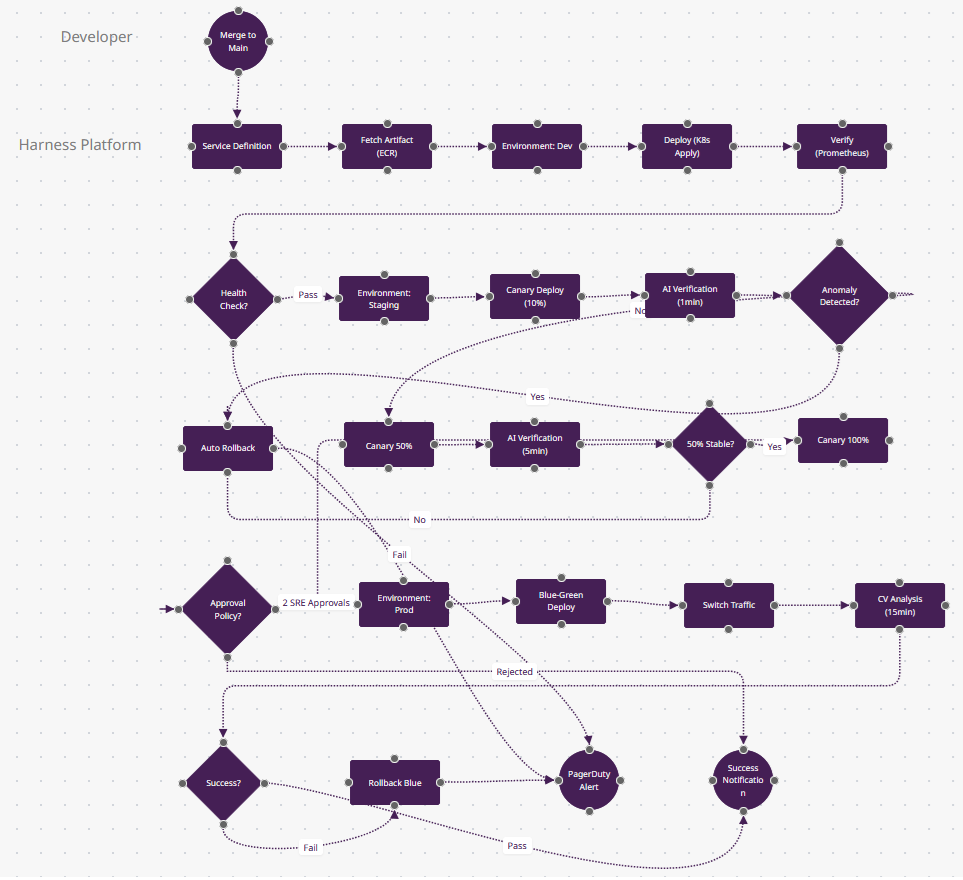
Ce qui Rend Harness Différent
- Vérification Continue par IA (n10-n11) : Les nœuds "AI Verification" utilisent le machine learning—Harness interroge Prometheus/Datadog pour les taux d'erreur, latence, débit, puis compare les métriques canary actuelles aux 3 derniers déploiements réussis. Si n11 "Anomaly Detected?" voit un pic de 5% du taux d'erreur (quand la baseline est 0,1%), n12 fait un auto-rollback. Aucun humain ne surveille les dashboards.
- Livraison Progressive Intégrée (n9→n13→n15) : Ce n'est pas juste "déployer 10% puis 50%"—Harness calcule les pourcentages de trafic, attend la stabilisation des métriques, et avance automatiquement. CircleCI/Jenkins nécessitent des scripts personnalisés ; le modèle de service de Harness traite canary/blue-green comme config déclarative.
- Optimisation des Coûts (invisible) : Entre n7-n8 (dev vers staging), Harness peut éteindre dev à 18h et redémarrer à 8h—autoscaling basé sur les heures de bureau. Le dashboard n20 "CV Analysis" montre les coûts de déploiement par service. Cette couche FinOps est unique à Harness/Octopus.
- Politiques d'Approbation en Code (n17) : "Approval Policy?" applique "2 approbations SRE requises pour la prod les vendredis"—écrit en OPA (Open Policy Agent). Pas une case à cocher dans l'UI ; c'est de la policy-as-code versionnée qui audite qui a approuvé quoi. Seuls Harness et Spinnaker font cela.
- Quand Choisir : Vous gérez plus de 100 microservices, avez besoin de rollback piloté par IA, voulez de la visibilité FinOps, ou nécessitez un RBAC entreprise (conformité SOC2/PCI). Équipes SRE à grande échelle (Salesforce, McAfee utilisent Harness).
7. Bitbucket Pipelines : CI/CD Natif Atlassian
Contexte : Bitbucket Pipelines offre un CI/CD Docker-first pour les équipes de l'écosystème Atlassian (Jira/Confluence). Configuré via bitbucket-pipelines.yml avec des Pipes—intégrations pré-construites pour AWS, Slack, SonarCloud. Chaque étape s'exécute dans un conteneur Docker, assurant des environnements cohérents. Idéal pour les workflows Agile centrés sur Jira.
Pourquoi les Développeurs le Choisissent : Pipelines spécifiques par branche, Jira Smart Commits (transition automatique des tickets), support Docker intégré, et déploiements visibles dans les releases Jira. Les Pipes éliminent le scripting bash pour les tâches courantes.
Patterns de Production : Images Docker personnalisées pour builds monorepo, étapes parallèles (lint+test), variables de déploiement par environnement, et clés SSH depuis les paramètres du repository.
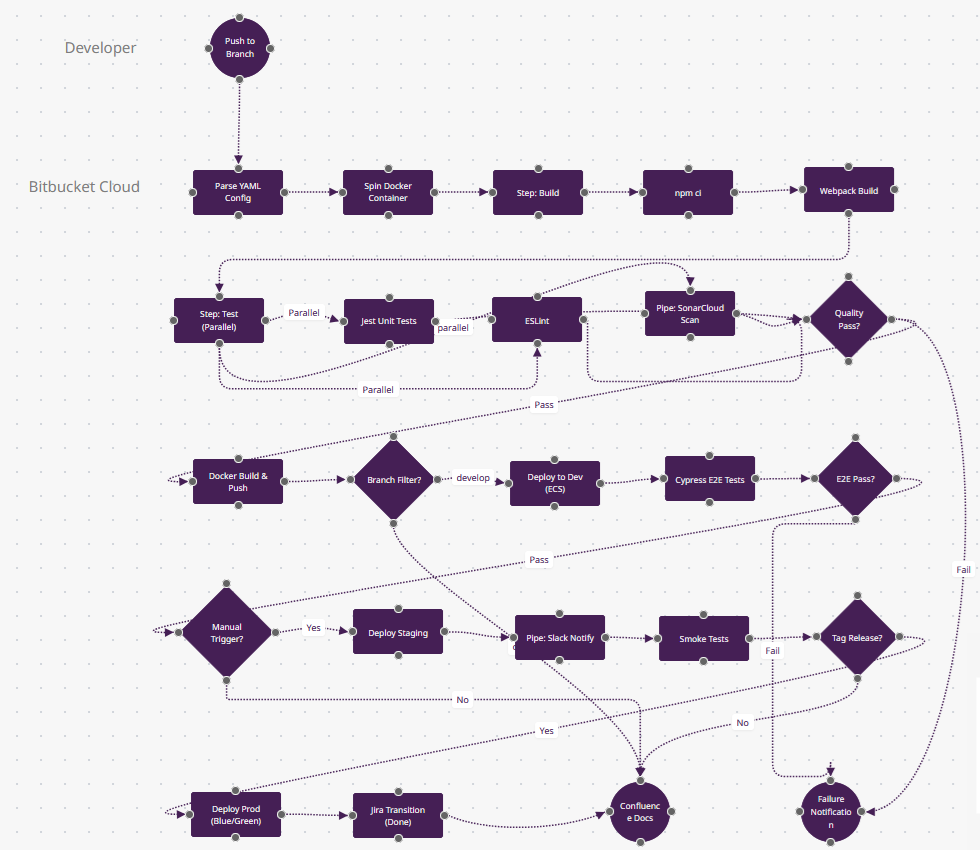
Télécharger Bitbucket-Pipelines.fz
Ce qui Rend Bitbucket Pipelines Différent
- Abstraction Pipes (n10, n19) : "Pipe: SonarCloud Scan" et "Pipe: Slack Notify" sont des conteneurs Docker pré-construits du marketplace Pipe d'Atlassian—une ligne de YAML remplace 50 lignes de bash. Contrairement aux plugins Jenkins (qui s'exécutent dans le contrôleur), les Pipes sont des conteneurs sandboxés. Les Orbs CircleCI sont similaires mais moins curatés.
- Jira Smart Commits (n23) : "Jira Transition (Done)" se produit parce que votre message de commit était
git commit -m "API-421 #done". Bitbucket parse cela et fait passer le ticket Jira API-421 à la colonne "Done"—pas de webhooks, juste la syntaxe de commit. GitHub Actions nécessite des appels API Jira. - Pipelines Spécifiques par Branche (n13) : Le losange "Branch Filter?" utilise le modèle de branches de Bitbucket—develop exécute n14 (deploy dev), release/* exécute staging, main exécute prod. C'est configuré en YAML mais visible dans l'UI dans la vue déploiement de Bitbucket—suit quelle branche est dans quel environnement.
- Étapes Docker-Native (n3) : Chaque étape s'exécute dans un conteneur Docker frais (spécifié par étape). n5 (npm ci) pourrait utiliser node:18-alpine, n11 (Docker Build) utilise docker:latest. Pas de scripts "installer Node, installer Docker"—chaque étape est isolée.
- Quand Choisir : Votre équipe vit dans Jira/Confluence, vous voulez des étapes Docker sans config, ou vous gérez des équipes Agile de 10-50 personnes nécessitant une intégration étroite SCM-suivi de tickets. Domine les organisations centrées sur Atlassian.
8. TeamCity : Gestion de Build Entreprise
Contexte : TeamCity de JetBrains excelle dans l'orchestration de chaînes de build—les builds dépendants se déclenchent automatiquement (backend→frontend→Docker). Les configs DSL Kotlin permettent des pipelines type-safe en code. Les fonctionnalités entreprise incluent la détection de tests instables, l'analytics d'échecs de build, et la gestion de pools d'agents. Populaire dans les environnements .NET/Java nécessitant des pistes d'audit.
Pourquoi les Développeurs le Choisissent : Réutilisation du cache de build entre branches (10x plus rapide), builds parallèles avec résolution intelligente des dépendances, tendances d'historique de tests, et agents cloud (AWS/Azure) qui scalent à la demande.
Patterns de Production : Builds composites (lib→service→deploy), dépendances d'artefacts (promouvoir le build #42 en prod), auto-assignation d'investigation (ML identifie les commits responsables), et règles de déclenchement VCS.

Ce qui Rend TeamCity Différent
- Chaînes de Build avec Dépendances (n4→n11→n16) : En production, "Build Chain: API" (n4) qui finit déclenche "Build Chain: Frontend" (n11) automatiquement—les dépendances snapshot signifient "le build Frontend #847 dépend du build API #423." Le losange n19 "Snapshot Dependency?" décide si cette chaîne a été déclenchée ou manuelle. Seuls TeamCity et Bamboo supportent cela.
- Détection de Tests Instables (n8-n9) : Le losange "Test Stability?" utilise le ML—si LoginTest échoue 3 fois puis passe, TeamCity le marque "instable" et le met en quarantaine (n10). Les tests instables ne bloquent pas les builds mais sont assignés aux devs pour correction. CircleCI nécessite des scripts personnalisés ; l'UI de TeamCity montre les tendances d'instabilité.
- Promotion d'Artefacts (n18→n22) : "Deploy to prod" ne reconstruit pas—il promeut l'image Docker exacte du build #423 (construit il y a 3 jours en dev). Le n18 "Push to Registry" la tague v1.2.3, et n22 déploie cet artefact immuable. Les autres outils reconstruisent depuis les sources ; TeamCity assure la cohérence binaire.
- DSL Kotlin (invisible) : La config du pipeline est du code Kotlin type-safe (pas du YAML)—votre IDE autocomplète les noms d'étapes, attrape les typos à la compilation. Les builds parallèles n6-n8 pourraient être une boucle forEach sur une liste. Seuls TeamCity et Bazel supportent les configs compilées.
- Quand Choisir : Vous avez des dépendances multi-repos complexes (monorepo .NET + Java + Node), avez besoin de traçabilité des artefacts de build, ou voulez un support IDE niveau IntelliJ pour le code de pipeline. Domine les environnements entreprise Java/C#.
9. Argo CD : GitOps pour Kubernetes
Contexte : Argo CD implémente GitOps—les manifests Kubernetes (YAML/Helm/Kustomize) dans Git deviennent la source de vérité. Argo synchronise continuellement l'état du cluster pour correspondre au repo, avec détection de drift et auto-réparation. Essentiel pour les équipes plateforme gérant plus de 10 clusters à travers dev/staging/prod. Déclaratif par conception (pas de scripts impératifs).
Pourquoi les Développeurs le Choisissent : Visualisation de l'état du cluster (live vs. désiré), rollback via Git revert, support multi-cluster (promouvoir l'app de cluster-dev à cluster-prod), et intégration SSO (RBAC par namespace).
Patterns de Production : Pattern app-of-apps (Argo gère sa propre config), sync waves (déployer la DB avant l'app), health checks (statut CRD), et hooks pre/post-sync (exécuter les migrations).

Ce qui Rend Argo CD Différent
- GitOps Pull-Based (boucle n3→n6) : La boucle [sync toutes les 3min] est l'architecture d'Argo—il pull depuis Git continuellement, sans attendre les webhooks. Si GitHub est down, Argo synchronise toujours depuis son repo en cache. Si quelqu'un fait
kubectl delete pod, n6 "Drift Detected?" le remarque dans les 3 minutes et n7 re-synchronise. Le CI/CD push-based (Jenkins, GitHub Actions) ne peut pas détecter les changements manuels. - Sync Waves Déclaratifs (n8-n11) : Ce ne sont pas des jobs séquentiels—les numéros de wave (0→1→2→3) disent à Kubernetes "appliquer le namespace d'abord, puis ConfigMap, puis Deployment." Si vous ajoutez un nouveau Secret (wave 1.5), Argo l'insère dans l'ordre automatiquement. Les hooks Helm sont similaires mais limités à install/upgrade ; Argo supporte n'importe quel type de ressource avec les sync waves.
- Évaluation de Santé Au-delà des Pods (n13-n14) : Le losange "Progressing?" ne vérifie pas juste le statut des pods—il lit les statuts des Custom Resources (ex: santé Istio VirtualService, émission de certificat Cert-Manager). n15 "Mark Healthy" ne se produit que quand tous les CRDs rapportent healthy. Jenkins/CircleCI vérifient juste HTTP 200 ; Argo comprend la sémantique Kubernetes.
- Pattern App-of-Apps (activé par n7) : Le hook pre-sync peut déployer Argo CD lui-même—vous avez une app Argo "infra" qui gère 50 apps Argo "service". Changez un values.yaml dans Git, et Argo met à jour récursivement les 50 services. Ce GitOps méta-niveau est impossible dans le CI/CD traditionnel.
- Quand Choisir : Vous gérez plus de 10 clusters Kubernetes, avez besoin de pistes d'audit pour la conformité (chaque changement est un commit Git), voulez la détection de drift, ou exécutez des plateformes multi-tenant. Le standard GitOps pour les équipes d'ingénierie plateforme.
10. AWS CodePipeline : Automatisation Cloud Native
Contexte : AWS CodePipeline orchestre le CI/CD entièrement dans AWS, se déclenchant sur les changements CodeCommit/GitHub/S3. Les stages utilisent CodeBuild (builds Docker), CodeDeploy (EC2/ECS/Lambda), et actions d'approbation manuelle. Idéal pour les architectures AWS-only nécessitant des déploiements cross-account ou l'intégration Step Functions.
Pourquoi les Développeurs le Choisissent : Permissions basées sur IAM, métriques CloudWatch pour la durée du pipeline, chiffrement S3 des artefacts, et intégration EventBridge (déclencher sur complétion de stack CloudFormation). Serverless-friendly (déploiement Lambda en secondes).
Patterns de Production : Déploiements multi-régions (us-east-1→eu-west-1), déploiements ECS blue-green avec shifting de trafic ALB, mises à jour de stacks CloudFormation, et notifications d'approbation SNS.
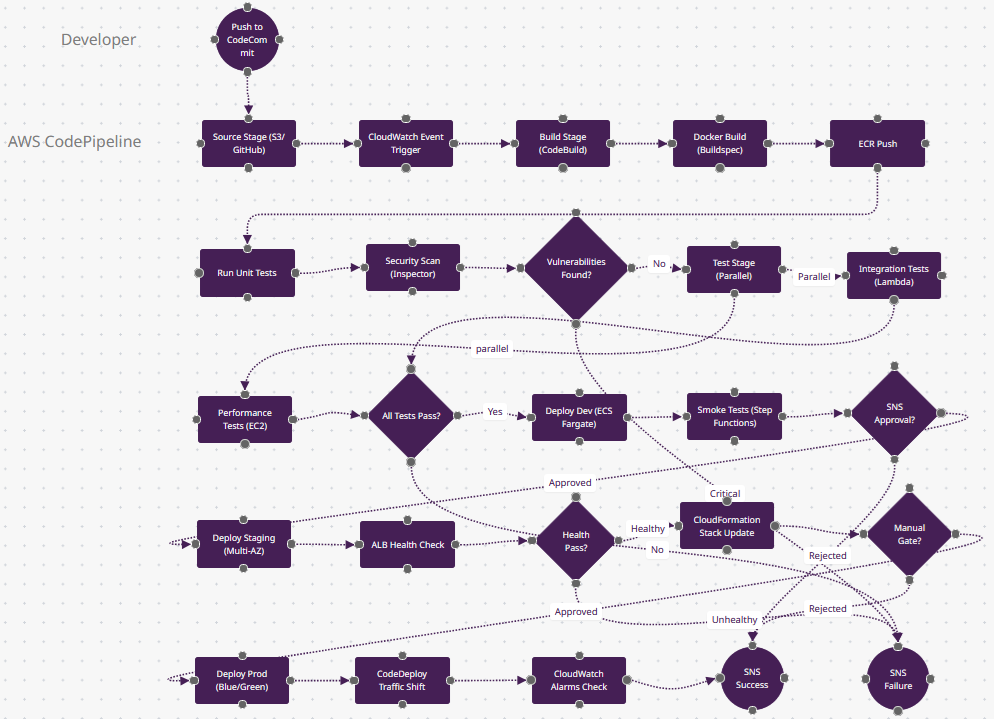
Télécharger AWS-CodePipeline.fz
Ce qui Rend AWS CodePipeline Différent
- Hiérarchie Stage-Action (n2→n4→n9) : CodePipeline structure en stages contenant des actions—n4 "Build Stage" contient les actions n5-n8 (build Docker, tests, scans). Dans l'UI, les stages sont des boîtes horizontales avec les actions comme étapes verticales. Ce modèle visuel (vs. les jobs plats de Jenkins) clarifie les portes de déploiement.
- Déploiements Cross-Account (simplifié en n22) : Les déploiements production utilisent AssumeRole pour déployer vers un compte AWS différent (compte prod 111, compte staging 222). Le n21 "Manual Gate?" applique "seul le rôle Deploy dans le compte prod peut approuver." La sécurité multi-compte est native ; les autres outils nécessitent des scripts IAM personnalisés.
- Intégration EventBridge (n3) : "CloudWatch Event Trigger" peut démarrer des pipelines sur uploads d'objets S3, complétions de stacks CloudFormation, ou changements d'état EC2—pas juste les pushs Git. Exemple : Upload d'un ZIP Lambda vers S3 → n3 déclenche → n5 build le conteneur → n22 déploie. Événementiel au-delà du SCM.
- CodeDeploy Traffic Shifting (n23) : "CodeDeploy Traffic Shift" utilise les cibles pondérées ALB/NLB—shift 10% du trafic vers la nouvelle tâche ECS, attendre 5 minutes en surveillant n24 "CloudWatch Alarms," puis shift 50%. Si les alarmes se déclenchent, auto-rollback. Cette orchestration blue-green est native AWS ; Kubernetes Ingress nécessite Flagger.
- Quand Choisir : Vous êtes AWS-only (pas de multi-cloud), avez besoin de gouvernance cross-account, voulez des déploiements Lambda serverless, ou intégrez avec Step Functions pour des workflows complexes. Le couplage étroit aux services AWS est le compromis pour la simplicité.
Conclusion
Ces 10 workflows représentent des patterns de production utilisés par les équipes d'ingénierie déployant du code des centaines de fois par jour. Les forces de chaque plateforme s'alignent avec des contextes organisationnels spécifiques—GitHub Actions pour la vélocité open-source, GitLab pour le DevSecOps orienté conformité, Jenkins pour les écosystèmes de plugins, et Argo CD pour le GitOps Kubernetes déclaratif. Copiez le FlowZap Code dans le playground sur flowzap.xyz pour visualiser et personnaliser ces diagrammes pour les pipelines de votre équipe.
Inspirations :
- JetBrains : L'État du CI/CD
- DevOpsBay : Statistiques et Adoption DevOps 2025
- Northflank : Meilleurs Outils CI/CD
- GitHub Actions vs GitLab CI vs Jenkins Comparaison 2025
- Developer Nation Report DN29
- Aziro : Top Fournisseurs de Services CI/CD
- Pieces : Meilleurs Outils CI/CD
- Spacelift : Statistiques DevOps
- Spacelift : Outils CI/CD
- DeployHQ : Meilleurs Logiciels CI/CD 2025
- Spacelift : Outils de Déploiement Continu